SQL bezeichnet eine Sprache für die Kommunikation mit relationalen Datenbanken, mit denen Daten aus diesen ausgelesen werden können.
Sie zeichnet sich durch ihre einfach gehaltene Syntax aus und besteht im Wesentlichen aus englischen Sprachelementen. Eine fertige SQL Anfrage lässt die
Datenbank eine Tabelle generieren, die sie dann zurückgibt.
Allgemein kann eine SQL-Abfrage aus folgenden Teilen bestehen:
SELECTFROMWHEREGROUP BYHAVINGORDER BY
Mit SELECT werden die Spalten ausgewählt, die später einmal im Ergebnis angezeigt werden. Dies wird Projektion genannt,
da bestimmte Tabellenspalten ausgewählt werden. Dabei sind folgende Parameter zugelassen:
* ( = alle Spalten )
Es gibt einen weiteren Parameter, der angegeben werden kann: DISTINCT. Mit diesem werden nur Einträge im Ergebnis zugelassen,
wenn sie nicht schon mal vorkommen, heißt, jedes Ergebnis taucht nur ein mal auf.
Nun müssen allerdings noch die Tabellen angegeben werden, von denen die Daten geholt werden sollen. Dies passiert mit FROM,
welches auch zu der Projektion gehört. Hierbei werden einfach alle benötigten Tabellen hinter das FROM geschrieben:
SELECT Spalte FROM Tabelle
SELECT Spalte, AndereSpalte FROM Tabelle, AndereTabelle
Wenn mal eine Spalte in zwei verschiedenen Tabellen unter dem gleichen Namen vorkommt, so muss bei der Spaltenauswahl die Tabelle mit angegeben werden:
SELECT Tabelle1.Spalte, Tabelle2.Spalte FROM Tabelle1, Tabelle2
Mit FROM können allerdings auch sogenannte JOINs erstellt werden. Ein JOIN verbindet zwei separate Tabellen zu einer großen unter Berücksichtigung von
bestimmten Bedingungen (ON). Man geht allgemein von zwei Tabellen aus, der linken und der rechten. Es gibt verschiedene Arten, diese beiden Tabellen dann zu verbinden:
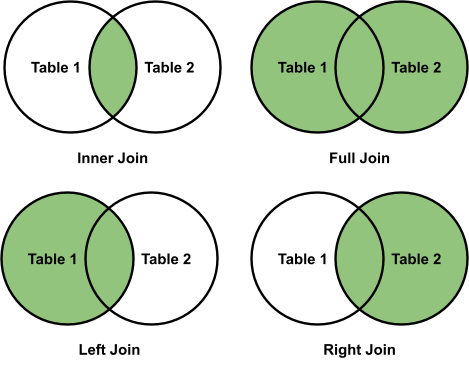
Ein INNER JOIN erstellt eine neue Tabelle, in denen nur diejenigen Einträge vorhanden sind, die in beiden Tabellen vorhanden sind.
Ein LEFT / RIGHT JOIN nimmt alle Einträge der linken / rechten Tabelle und nur diejenigen aus der jeweils anderen, die zu den anderen Datensätzen passen.
Ein FULL JOIN verbindet alle möglichen Kombinationen mit zueinander passenden Datensätzen und kann möglicherweise eine sehr große Tabelle generieren.
Ein JOIN in SQL sieht so aus:
Diese Abfrage im Speziellen vereint die Tabellen Bestellungen (links) und Kunden (rechts) dort, wo die KundenID gleich ist.
Danach sortiert er aber alle Kunden aus, deren Namen nicht mit einem T beginnen (später mehr dazu).
Wenn mehr als zwei Tabellen vereint werden sollen, so kann mit geschickter Klammersetzung das Ergebnis des ersten JOINs als linke oder rechte
Tabelle für den zweiten JOIN dienen.
Mit den anderen Anweisungen werden aus den Spalten die Zeilen ausgewählt, darum nennt sich dieser Schritt Selektion.
Mit WHERE können, wie auch schon im Beispiel oben, Zeilen heraussortiert werden, die einer bestimmten Bedingung entsprechen.
Der Bedingungsausdruck, der diese Auswahl trifft, kann aus folgenden Operatoren bestehen:
| Arithmetische | Vergleich | Selektion | Logische |
|---|---|---|---|
+ (plus) |
= (gleich) |
IN / NOT IN (muss / darf nicht in Menge liegen) |
AND (beide Bed. müssen erfüllt sein) |
- (minus) |
<> (ungleich) |
BETWEEN / NOT BETWEEN … AND … (Wert innerhalb / außerhalb von Bereich) |
OR (eine der beiden Bed. muss erfüllt sein) |
* (mal) |
> (größer) |
LIKE / NOT LIKE (Vergleichsmuster) |
NOT (Bed. darf nicht erfüllt sein) |
/ (geteilt) |
< (kleiner) |
IS NULL / IS NOT NULL (leer/nicht leer) |
|
% (modulo) |
>= (größer gleich) |
||
<= (kleiner gleich) |
Wenn ein Text verglichen werden soll, muss LIKE verwendet werden. Hierbei können sogenannte „Wild Cards” verwendet werden,
welche als Joker innerhalb eines Textes dienen:
% * |
beliebig viele Zeichen (0..n) | bl% |
bl, black, blue & blob |
_ ? |
ein einzelnes Zeichen | h_t |
hot, hat & hit |
# |
eine Ziffer | 2#5 |
205, 215, ... |
[] |
Zeichen innerhalb der Klammern | h[oa]t |
hot & hat, aber nicht hit |
[^!] |
Zeichen nicht in den Klammern | h[^oa]t |
hit, aber nicht hot und hat |
[-] |
Eine Reihe an Zeichen | c[a-b]t |
cat & cbt |
Manchmal gibt es mehrere verschiedene, die das gleiche tun.
Einige Beispiele für WHERE:
Aggregatfunktionen (auch Spaltenfunktionen) fassen die Werte einer gesamten Spalte zu einem kombinierten (aggregierten) Wert zusammen.
COUNT Zählt die Zeilen, deren Werte nicht NULL sindAVG durchschnittlicher WertMAX größter WertMIN kleinster WertSUM Summe (alle Werte addiert)
Bei SELECT dürfen, wenn Aggregatfunktionen in der Ergebnistabelle vorkommen, keine anderen Spalten außer Aggregatfunktionen und Spalten,
nach denen gruppiert wurde, angegeben werden. Das heißt, das hier wäre möglich:
SELECT COUNT(*), AVG(Preis) FROM Bestellung;
Das hier allerdings nicht:
SELECT SUM(Stunden), NutzerID FROM Arbeitszeit;
Bei Aggregatfunktionen ist es sinnvoll, die Spalten umzubenennen, da es ansonsten nicht immer klar ist, um was es sich in der Spalte handelt. Dies geschieht mit einem AS.
Tabellennamen können ebenfalls umbenannt werden, indem einfach der neue Name hinter den eigentlichen Namen geschrieben wird.
SELECT SUM(Be.Preis) AS Gesamtpreis FROM Bestellung Be;
Gruppenfunktionen werden mit GROUP BY angekündigt.
GROUP BY bewirkt eine Teilmengenbildung der Tabelle entsprechend des angegebenen Attributs nachdem FROM und WHERE verarbeitet wurden, damit auch nach den JOINsSELECT genannt werden, nach denen gruppiert wurde
Mit HAVING können dann Bedingungen auf diese einzelnen Gruppen angewandt werden. Der Unterschied zwischen HAVING und WHERE:
WHERE eliminiert einzelne ZeilenHAVING eliminiert einzelne GruppenEin Beispiel:
Hier wird zunächst nach der ProduktID gruppiert. Dann werden alle Gruppen ausgeschlossen, die mehr als 12 mal im Durchschnitt gekauft werden,
um diese dann mit ihrer ProduktID, der Summe der gekauften Menge und der Durchschnittsmenge anzuzeigen.
Nun bleibt nur noch die ORDER BY-Anweisung. Diese sortiert das Ergebnis der SQL-Abfrage noch einmal alphabetisch, bzw. nach Größe der Zahl.
Mit ASC und DESC lässt sich zudem festlegen, ob das Ergebnis auf- oder absteigend sortiert werden soll. Es können auch mehrere Spalten je mit
ASC oder DESC angegeben werden, je mit einem , getrennt.
SELECT * FROM Kunden ORDER BY KundenName DESC, KundenID ASC;
Zuletzt noch ein Blick auf die Reihenfolge, in der die Datenbank die SQL-Anfrage bearbeitet:
FROM Zunächst werden alle hier aufgeführten Tabellen in eine Hilfstabelle geladenWHERE Alle Zeilen, die der Bedingung entsprechen, werden hier in eine Zwischentabelle zusammengefasstGROUP BY Auf der Basis der Gruppierungsattribute werden die Zeilen mit gleichen Attributen zusammengefasstHAVING Gruppen aus dem GROUP BY-Ergebnis werden nach der HAVING-Bedingung ausgewähltSELECT Erst jetzt wird ausgewählt, welche Spalten in dem endgültigen Ergebnis angezeigt werden sollenORDER BY Ändert nur noch die Reihenfolge der Zeilen im Endergebnis